


Executive Summary
Lately, I’ve been investing time into auditing packet sockets source code in the Linux kernel. This led me to the discovery of CVE-2020-14386, a memory corruption vulnerability in the Linux kernel. Such a vulnerability can be used to escalate privileges from an unprivileged user into the root user on a Linux system. In this blog, I will provide a technical walkthrough of the vulnerability, how it can be exploited and how Palo Alto Networks customers are protected.
A few years ago, several vulnerabilities were discovered in packet sockets (CVE-2017-7308 and CVE-2016-8655), and there are some publications, such as this one in the Project Zero blog and this in Openwall, which give some overview of the main functionality.
Specifically, in order for the vulnerability to be triggerable, we need the kernel to have AF_PACKET sockets enabled (CONFIG_PACKET=y) and the CAP_NET_RAW privilege for the triggering process, which can be obtained in an unprivileged user namespace if user namespaces are enabled (CONFIG_USER_NS=y) and accessible to unprivileged users. Surprisingly, this long list of constraints is satisfied by default in some distributions, like Ubuntu.
Palo Alto Networks Cortex XDR customers can prevent this bug with a combination of the Behavioral Threat Protection (BTP) feature and Local Privilege Escalation Protection module, which monitor malicious behaviors across a sequence of events, and immediately terminate the attack when it is detected.
Technical Details
(All of the code figures on this section are from the 5.7 kernel sources.)
Due to the fact that the implementation of AF_PACKET sockets was covered in-depth in the Project Zero blog, I will omit some details that were already described in that article (such as the relation between frames and blocks) and go directly into describing the vulnerability and its root cause.
The bug stems from an arithmetic issue that leads to memory corruption. The issue lies in the tpacket_rcv function, located in (net/packet/af_packet.c) .
The arithmetic bug was introduced on July 19, 2008, in the commit 8913336 (“packet: add PACKET_RESERVE sockopt”). However, it became triggerable for memory corruption only in February 2016, in the commit 58d19b19cd99 (“packet: vnet_hdr support for tpacket_rcv“). There were some attempts to fix it, such as commit bcc536 (“net/packet: fix overflow in check for tp_reserve”) in May 2017 and commit edb58be (“packet: Don’t write vnet header beyond end of buffer”) in August 2017. However, those fixes were not enough to prevent memory corruption.
Let’s first have a look at the PACKET_RESERVE option:In order to trigger the vulnerability, a raw socket (AF_PACKET domain, SOCK_RAW type ) has to be created with a TPACKET_V2 ring buffer and a specific value for the PACKET_RESERVE option.

The headroom that is mentioned in the manual is simply a buffer with size specified by the user, which will be allocated before the actual data of every packet received on the ring buffer. This value can be set from user-space via the setsockopt system call.
| case PACKET_RESERVE:
{ unsigned int val; if (optlen != sizeof(val)) return -EINVAL; if (copy_from_user(&val, optval, sizeof(val))) return -EFAULT; if (val > INT_MAX) return -EINVAL; lock_sock(sk); if (po->rx_ring.pg_vec || po->tx_ring.pg_vec) { ret = -EBUSY; } else { po->tp_reserve = val; ret = 0; } release_sock(sk); return ret; } |
Figure 1. Implementation of setsockopt – PACKET_RESERVE
As we can see in Figure 1, initially, there is a check that the value is smaller than INT_MAX. This check was added in this patch to prevent an overflow in the calculation of the minimum frame size in packet_set_ring. Later, it’s verified that pages were not allocated for the receive/transmit ring buffer. This is done to prevent inconsistency between the tp_reserve field and the ring buffer itself.
After setting the value of tp_reserve, we can trigger allocation of the ring buffer itself via the setsockopt system call with optname of PACKET_RX_RING:
| Create a memory-mapped ring buffer for asynchronous packet reception. |
Figure 2. From manual packet – PACKET_RX_RING option.
This is implemented in the packet_set_ring function. Initially, before the ring buffer is allocated, there are several arithmetic checks on the tpacket_req structure received from user-space:
| min_frame_size = po->tp_hdrlen + po->tp_reserve;
… … if (unlikely(req->tp_frame_size < min_frame_size)) goto out; |
Figure 3. Part of the sanity checks in the packet_set_ring function.
As we can see in Figure 3, first, the minimum frame size is calculated, and then it is verified versus the value received from user-space. This check ensures that there is space in each frame for the tpacket header structure (for its corresponding version) and tp_reserve number of bytes.
Later, after doing all the sanity checks, the ring buffer itself is allocated via a call to alloc_pg_vec:
| order = get_order(req->tp_block_size);
pg_vec = alloc_pg_vec(req, order); |
Figure 4. Calling the ring buffer allocation function in the packet_set_ring function.
As we can see from the figure above, the block size is controlled from user-space. The alloc_pg_vec function allocates the pg_vec array and then allocates each block via the alloc_one_pg_vec_page function:
| static struct pgv *alloc_pg_vec(struct tpacket_req *req, int order)
{ unsigned int block_nr = req->tp_block_nr; struct pgv *pg_vec; int i; pg_vec = kcalloc(block_nr, sizeof(struct pgv), GFP_KERNEL | __GFP_NOWARN); if (unlikely(!pg_vec)) goto out; for (i = 0; i < block_nr; i++) { pg_vec[i].buffer = alloc_one_pg_vec_page(order); |
Figure 5. alloc_pg_vec implementation.
The alloc_one_pg_vec_page function uses __get_free_pages in order to allocate the block pages:
| static char *alloc_one_pg_vec_page(unsigned long order)
{ char *buffer; gfp_t gfp_flags = GFP_KERNEL | __GFP_COMP | __GFP_ZERO | __GFP_NOWARN | __GFP_NORETRY; buffer = (char *) __get_free_pages(gfp_flags, order); if (buffer) return buffer; |
Figure 6. alloc_one_pg_vec_page implementation.
After the blocks allocation, the pg_vec array is saved in the packet_ring_buffer structure embedded in the packet_sock structure representing the socket.
When a packet is received on the interface, the socket bound to the tpacket_rcv function will be called and the packet data, along with the TPACKET metadata, will be written into the ring buffer. In a real application, such as tcpdump, this buffer is mmap’d to the user-space and packet data can be read from it.
The Bug
Now let’s dive into the implementation of the tpacket_rcv function (Figure 7). First, skb_network_offset is called in order to extract the offset of the network header in the received packet into maclen. In our case, this size is 14 bytes, which is the size of an ethernet header. After that, netoff (which represents the offset of the network header in the frame) is calculated, taking into account the TPACKET header (fixed per version), the maclen and the tp_reserve value (controlled by the user).
However, this calculation can overflow, as the type of tp_reserve is unsigned int and the type of netoff is unsigned short, and the only constraint (as we saw earlier) on the value of tp_reserve is to be smaller than INT_MAX.
| if (sk->sk_type == SOCK_DGRAM) {
… else { unsigned int maclen = skb_network_offset(skb); netoff = TPACKET_ALIGN(po->tp_hdrlen + (maclen < 16 ? 16 : maclen)) + po->tp_reserve; if (po->has_vnet_hdr) { netoff += sizeof(struct virtio_net_hdr); do_vnet = true; } macoff = netoff – maclen; } |
Figure 7. The arithmetic calculation in tpacket_rcv
Also shown in Figure 7, if the PACKET_VNET_HDR option is set on the socket, sizeof(struct virtio_net_hdr) is added to it in order to account for the virtio_net_hdr structure, which should be right beyond the ethernet header. And finally, the offset of the ethernet header is calculated and saved into macoff.
Later in that function, seen in Figure 8 below, the virtio_net_hdr structure is written into the ring buffer using the virtio_net_hdr_from_skb function. In Figure 8, h.raw points into the currently free frame in the ring buffer (which was allocated in alloc_pg_vec).
| if (do_vnet &&
virtio_net_hdr_from_skb(skb, h.raw + macoff – sizeof(struct virtio_net_hdr), vio_le(), true, 0)) goto drop_n_account; |
Figure 8. Call to virtio_net_hdr_from_skb function in tpacket_rcv
Initially, I thought it might be possible to use the overflow in order to make netoff a small value, so macoff could receive a larger value (from the underflow) than the size of a block and write beyond the bounds of the buffer.
However, this is prevented by the following check:
| if (po->tp_version <= TPACKET_V2) {
if (macoff + snaplen > po->rx_ring.frame_size) { … … snaplen = po->rx_ring.frame_size – macoff; if ((int)snaplen < 0) { snaplen = 0; do_vnet = false; } } |
Figure 9. Another arithmetic check in the tpacket_rcv function.
This check is not sufficient to prevent memory corruption, as we can still make macoff a small integer value by overflowing netoff. Specifically, we can make macoff smaller than sizeof(struct virtio_net_hdr), which is 10 bytes, and write behind the bounds of the buffer using virtio_net_hdr_from_skb.
The Primitive
By controlling the value of macoff, we can initialize the virtio_net_hdr structure in a controlled offset of up to 10 bytes behind the ring buffer. The virtio_net_hdr_from_skb function starts by zeroing out the entire struct and then initializing some fields within the struct based on the skb structure.
| static inline int virtio_net_hdr_from_skb(const struct sk_buff *skb,
struct virtio_net_hdr *hdr, bool little_endian, bool has_data_valid, int vlan_hlen) { memset(hdr, 0, sizeof(*hdr)); /* no info leak */ if (skb_is_gso(skb)) { … if (skb->ip_summed == CHECKSUM_PARTIAL) { … |
Figure 10. Implementation of the virtio_net_hdr_from_skb function.
However, we can set up the skb so only zeros will be written into the structure. This leaves us with the ability to zero 1-10 bytes behind a __get_free_pages allocation. Without doing any heap manipulation tactics, an immediate kernel crash will occur.
POC
A POC code for triggering the vulnerability can be found in the following Openwall thread.
Patch
I submitted the following patch in order to fix the bug.
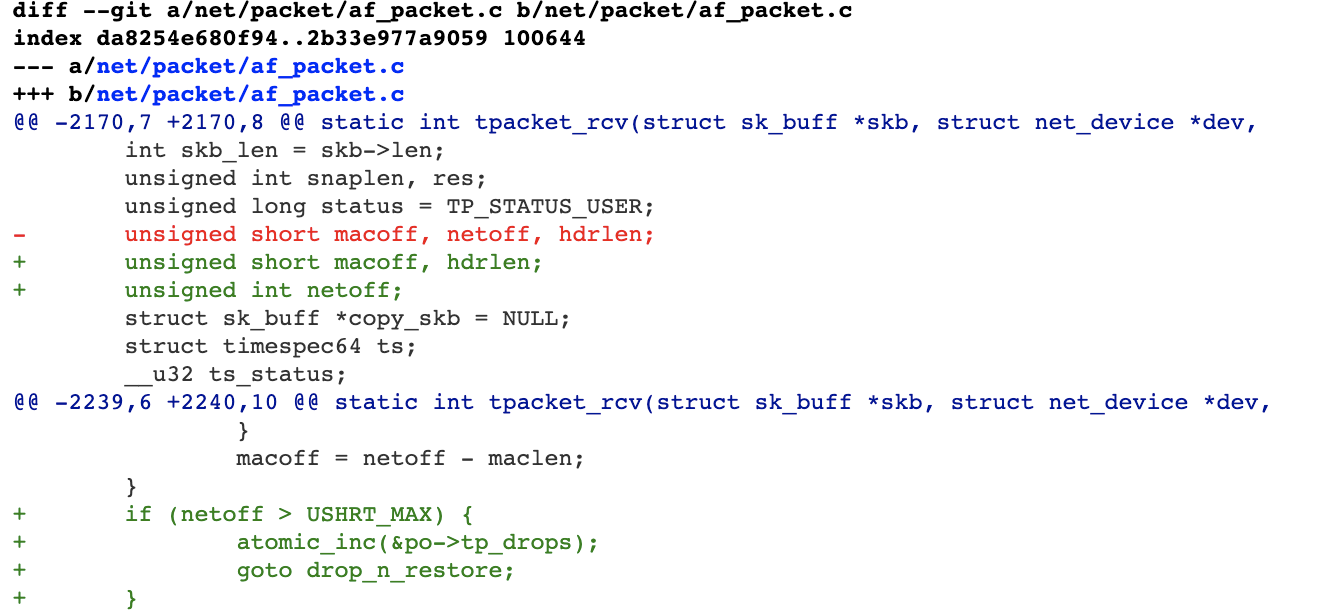
Figure 11. My proposed patch for the bug.
The idea is that if we change the type of netoff from unsigned short to unsigned int, we can check whether it exceeds USHRT_MAX, and if so, drop the packet and prevent further processing.
Idea for Exploitation
Our idea for exploitation is to convert the primitive to a use-after-free. For this, we thought about decrementing a reference count of some object. For example, if an object has a refcount value of 0x10001, the corruption would look as follows:

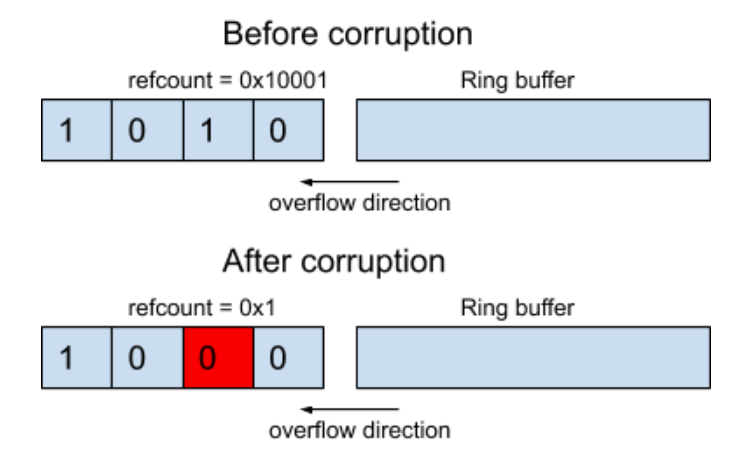
Figure 12. Zeroing out a byte in an object refcount.
As we can see in Figure 13 below, after corruption, the refcount will have a value of 0x1, so after releasing one reference, the object will be freed.
However, in order to make this happen, the following constraints have to be satisfied:
- The refcount has to be located in the last 1-10 bytes of the object.
- We need to be able to allocate the object at the end of a page.
- This is because get_free_pages returns a page-aligned address.
We used some grep expressions along with some manual analysis of code, and we came out with the following object:
| struct sctp_shared_key {
struct list_head key_list; struct sctp_auth_bytes *key; refcount_t refcnt; __u16 key_id; __u8 deactivated; }; |
Figure 13. Definition of the sctp_shared_key structure.
It seems like this object satisfies our constraints:
- We can create an sctp server and a client from an unprivileged user context.
- Specifically, the object is allocated in the sctp_auth_shkey_create function.
- We can allocate the object at the end of a page.
- The size of the object is 32 bytes and it is allocated via kmalloc. This means the object is allocated in the kmalloc-32 cache.
- We were able to verify that we can allocate a kmalloc-32 slab cache page behind our get_free_pages allocation. So we will be able to corrupt the last object in that slab cache page.
- Because of the reason 4096 % 32 = 0, there is no spare space in the end of the slab page, and the last object is allocated right behind our allocation. Other slab cache sizes may not be good for us, such as 96 bytes, because 4096 % 96 != 0.
- We can corrupt the highest 2 bytes of the refcnt field.
- After compilation, the size of key_id and deactivated is 4 bytes each.
- If we use the bug to corrupt 9-10 bytes, we will corrupt the 1-2 most significant bytes of the refcnt field.
Conclusion
I was surprised that such simple arithmetic security issues still exist in the Linux kernel and haven’t been previously discovered. Also, unprivileged user namespaces expose a huge attack surface for local privilege escalation, so distributions should consider whether they should enable them or not.
Palo Alto Networks Cortex XDR stops threats on endpoints and coordinates enforcement with network and cloud security to prevent successful cyber attacks. To prevent the exploitation of this bug, the Behavioral Threat Protection (BTP) feature and Local Privilege Escalation Protection module in Cortex XDR would monitor malicious behaviors across a sequence of events and immediately terminate the attack when detected.
To read the original article:https://unit42.paloaltonetworks.com/cve-2020-14386/